Umsetzung des ER-Modells ins Coddsche Relationen-Modell
Es gibt keine Möglichkeit, ein ER-Modell direkt in die Datenbank zu überführen, da diese Form sehr allgemein gehalten ist und keinerlei Aussagen über die Datentypen getroffen werden. Als Vorraussetzung für die Implementierung muss man dieses deshalb in dasCodd’sche Relationen-Modell überführen. Ziel dieser Umsetzung ist es, leicht handhabbareTabellen zu schaffen, die möglichst keine Redundanzen enthalten. (Redundanz = mehrfachesAuftreten derselben Daten �� Speicherverschwendung und Probleme beim Einfügen, Ändernbzw. Löschen von Datensätzen)Vier Regeln dienen der schrittweisen Erzeugung einfacher Relationen (Normalisierung).
Regel 1: eindeutige Abbildung der Wertebereiche des ERM auf dem CRM!
Regel 2: Jeder Entity-Typ (mit allen Attributen) wird genau in einer Relation (Tabelle)zusammengefasst.
Regel 3: Jeder Relationship-Typ in einer n:m-Beziehung wird ebenfalls auf einer Relation(Tabelle) abgebildet.
Regel 4: Bei 1:1-, 1:n- oder n:1-Relationships werden keine eigenen Relationen gebildet,sondern der Primärschlüssel der 1-er Seite wird der anderen Seite als Fremdschlüsselzugefügt.
Wahl des Datenbank-Management-Systems (DBMS)
Die nichtprozeduale Sprache SQL hat sich als Industriestandard im Bereich der relationalen Datenbanken durchgesetzt. Hier teilt man der Sprache nicht mit, wie eine Aufgabe gelöst werden soll, sondern nur was man als Ergebnis bekommen möchte. Auf dem Markt gibt es eine Vielzahl von kostenpflichtigen SQL-Datenbanksystemen, darunter Microsoft SQL Server oder Oracle.
Für Schulen eignet sich das MySQL Datenbanksystem besonders, weil es für diese kostenlos zur Verfügung gestellt wird. Das Pendant von Microsoft scheidet aufgrund der hohen Lizenzierungskosten von vorn herein aus. MySQL lässt viele Möglichkeit des Zugriffs von unterschiedlichsten Programmiersprachen zu. So könnte man mit geringem Aufwand die Datenbank vom Internet aus über PHP abrufen.
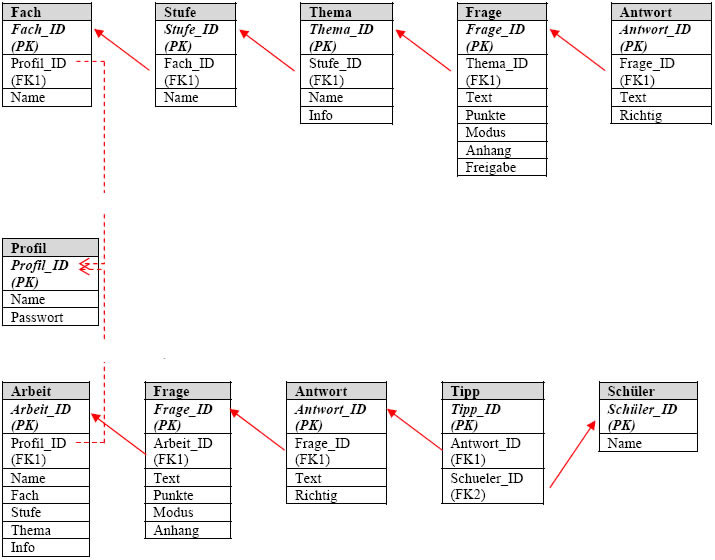
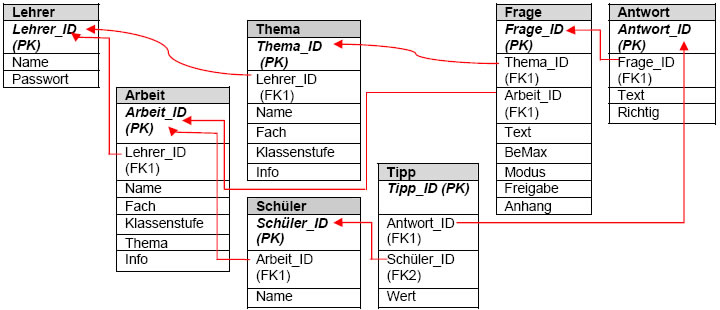
Anpassung der Datenbankstruktur
Die entwickelte Datenbankstruktur erwies sich im Laufe der Umsetzung in die Zieldatenbank als unzureichend, da bei nachträglicher Änderung von Frage- bzw. Antwort-Datensätzen gleichzeitig die bisher erzielten Ergebnisse der Schüler verfälscht werden. Es wurde klar, dass es sich nicht vermeiden lässt, Redundanzen der Fragen inklusive der zugeordneten Antworten zu schaffen. Die benötigten „Frage-“ und „Antwort“-Datensätze werden hierzu in die extra Datenbank „Arbeitenkatalog“ gespiegelt, so bleiben alle Ergebnisse unabhängig von nachträglichen Veränderungen bestehen. Die zusätzlich benötigte Datenbank lässt sich einfach von den bisherigen Tabellen ableiten. Die Tabellen „Schüler“ und „Tipp“ werden in die neue Datenbank „Arbeitenkatalog“ verschoben. Auf diese Weise ist gleichzeitig der Datenschutz besser zu gewährleisten.
Gleichzeitig wurde der bestehende „Fragenkatalog“, zur Vermeidung von Redundanzen zwischen mehreren Themenbereichen, durch die Tabellen „Fach“ und „Stufe“ ergänzt. Diese werden durch 1:n-Beziehungen zwischen den Tabellen „Profil“ und „Thema“ eingeordnet. Die dabei erneut entstandenen Redundanzen gewährleisten die Unabhängigkeit der verschiedenen Profile. Eine direkte Verknüpfung der Tabellen „Fach“ und „Stufe“ mit der Tabelle „Thema“ könnte zu Problemen beim Ändern bzw. Löschen von Datensätzen führen. Der gleichzeitige Betrieb von mehreren Server-Programmen wäre dadurch gefährdet. Die „Lehrer“-Tabelle wird extern in einer weiteren Datenbank aufbewahrt, da ansonsten weitere unnötige Redundanzen zwischen „Arbeiten-“ und „Fragenkatalog“ entstünden.